State-of-the-Art Performance with 10x Less Data
 GroundCUA
GroundCUA
Grounding Computer Use Agents
on Human Demonstrations
Achieving SOTA desktop grounding with 700K samples vs 9M+ in prior work
Dense supervision • Expert annotations • Cross-platform generalization
60.3%
Desktop Avg
85.8%
Corss-Platform Avg
50.6%
OSWorld Agent
3.56M+
Human Annotations
56K
Screenshots
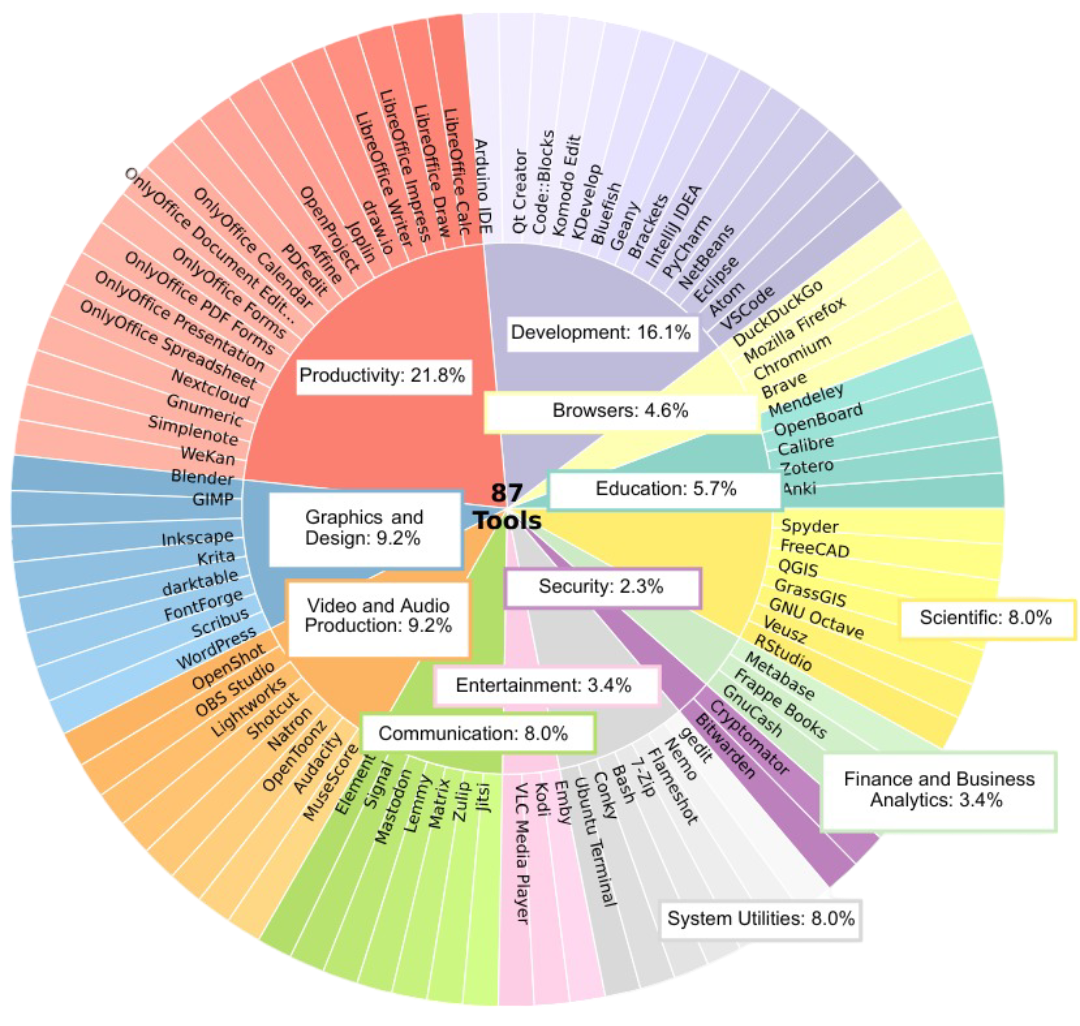
87
Applications
10x
Data Efficient